
NLP in Finance and Accounting (VI): Generative LLM
Published:
This is the sixth post of the series on NLP in finance and accounting. In this post, we will talk about the use of generative large language models (LLMs) in finance research.
Rise of Generative LLM
The launch of ChatGPT on November 30, 2022, brought significant attention towards generative LLMs, including OpenAI’s GPT, Google Bard, and Meta’s LLaMa. These models are built on transformer architecture and excel in text generation. Compared to BERT, generative LLMs usually require more extensive training data and parameters, with fewer options for fine-tuning. In application, BERT is more capable of interpretive tasks, while generative LLM is adept at generative task, especially when creativity is needed.
Applications of Generative LLM
Here is an overview of the applications of generative LLM in finance research, though not exhaustive. In other fields, for example economics, researchers have been exploring the feasibility of replacing human participants in experiment with models like ChatGPT.
1. Summarization
The first application is summarization. Researchers have leveraged these models to condense lengthy texts into concise summaries, and develop measures on information content.
Kim et al. (2023a): they instruct GPT-3.5 Turbo to summarize MD&A and conference call transcripts. The summaries are much shorter, around 25%-30% compared to original length. At the same time, summaries are more informative that they have greater power in explaining stock market reaction (abnormal return around the disclosure). Built on this, they construct a “Bloat” measure, the relative amount by which a document’s length is reduced, to capture the degree of redundant information in corporate disclosure. They find “Bloat” is associated with adverse capital market consequences, such as lower price efficiency and higher information asymmetry.
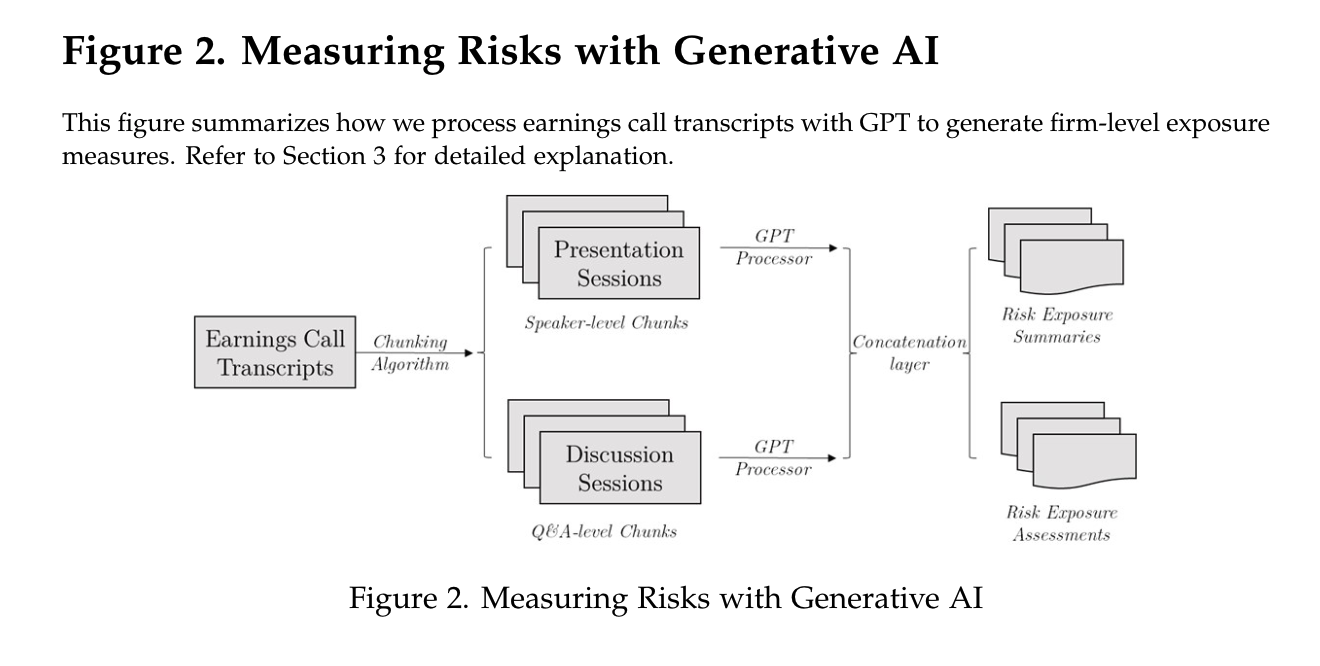
Kim et al. (2023b): they instruct GPT-3.5 Turbo to generate risk summaries and assessments from conference call transcripts. They construct the risk exposure measure based on the length of risk summaries (assessments) relative to the length of transcripts. They show that GPT-based risk measures possess significant information content and outperform the existing risk measures in predicting (abnormal) firm-level volatility and firms’ choices such as investment and innovation.
2. Question Answering
The second application is question answering, which takes advantage of GPT’s ability to generate human-like responses.
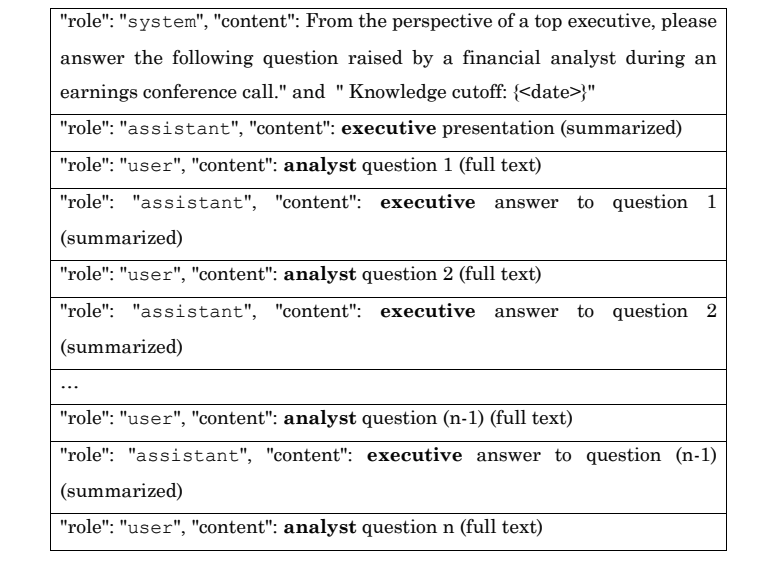
- Bai et al. (2023): they ask generative LLM (GPT-3.5, Google Bard, StableLM) to answer questions at conference call based on all information presented in the call before the given question is asked. By comparing the actual response from managers to GPT’s response, they construct “HAID” (Human-AI Differences), as one minus the similarity of human and AI responses. They find HAID strongly predicts stock liquidity, abnormal returns, analyst forecast accuracy following these calls, and propensity of managers to provide management guidance, consistent with HAID capturing new information conveyed by managers.
3. Classification or Scoring
The third application involves classification or scoring tasks, which are also prevalent in BERT. While BERT typically relies on human-labelled data for fine-tuning, generative language models require far fewer examples, often employing zero-shot, one-shot, or few-shot learning approaches.
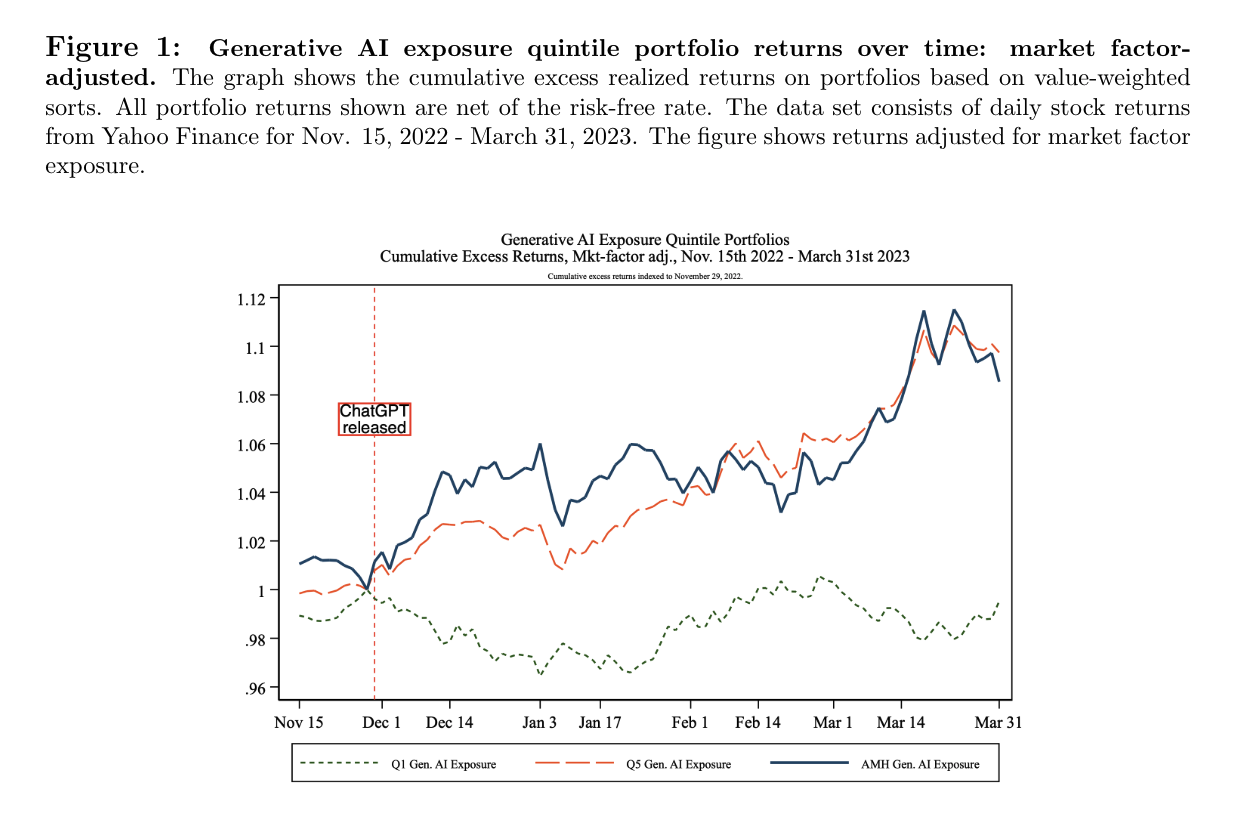
- Eisfeldt et al. (2023): they construct a firm-level measure of workforce exposure to generative AI by asking GPT-3.5 Turbo to categorize whether a task can be performed by current or future version of ChatGPT. Then the task-level AI exposure measures are aggregated to occupation-level according to O*NET. Finally, the occupations are mapped to public firms based on employee profile data from Revelio Labs. A portfolio that long firms with high AI exposures and short firms with low AI exposures earned over 9% from the released date through March 31, 2023.
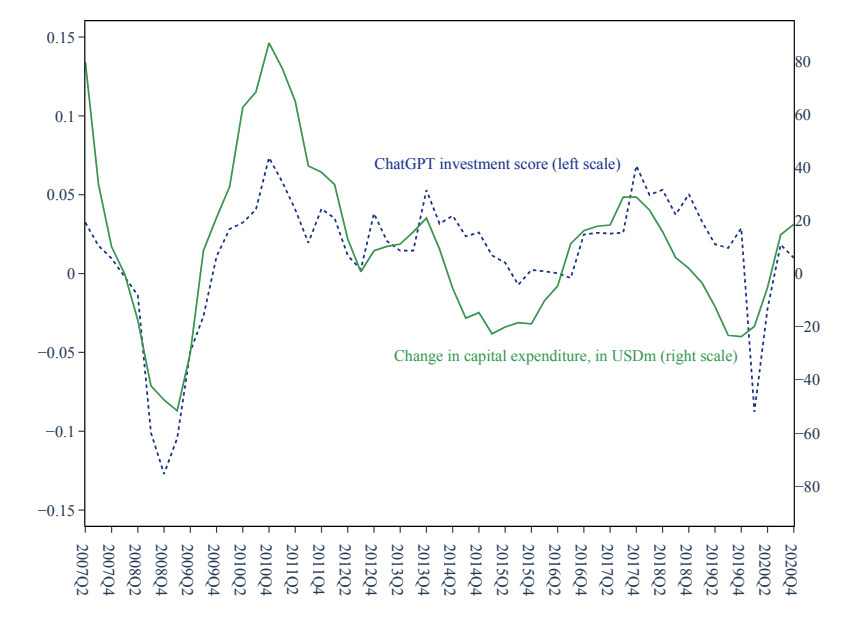
- Jha et al. (2023): they ask GPT-3.5 to rate “How does the firm plan to change its capital spending over the next year?” from decrease substantially (-1), decrease (-0.5), no change (0), increase (0.5), increase substantially (1), and provide a one-sentence explanation. Then an “Investment Score” is constructed based on GPT’s response. They show that this “Investment Score” predicts higher future capital expenditure and R&D, and lower abnormal returns, suggesting it provides incremental information.
4. Embeddings
The last application is embeddings, a process where textual data is transformed into numerical vectors. Generative LLMs are more advanced as they go beyond word frequency or co-occurrences, they also capture semantic and syntactic information.
- Chen et al. (2022): they use LLMs (BERT, RoBERTa, OPT) to convert news articles into embeddings (vectors), then use it for sentiment analysis and portfolio construction. They show that the long-short portfolio based on OPT and RoBERTa consistently outperform word-based models like Word2Vec and SESTM, suggesting that the semantic and syntactic information that LLMs capture is crucial in investment.
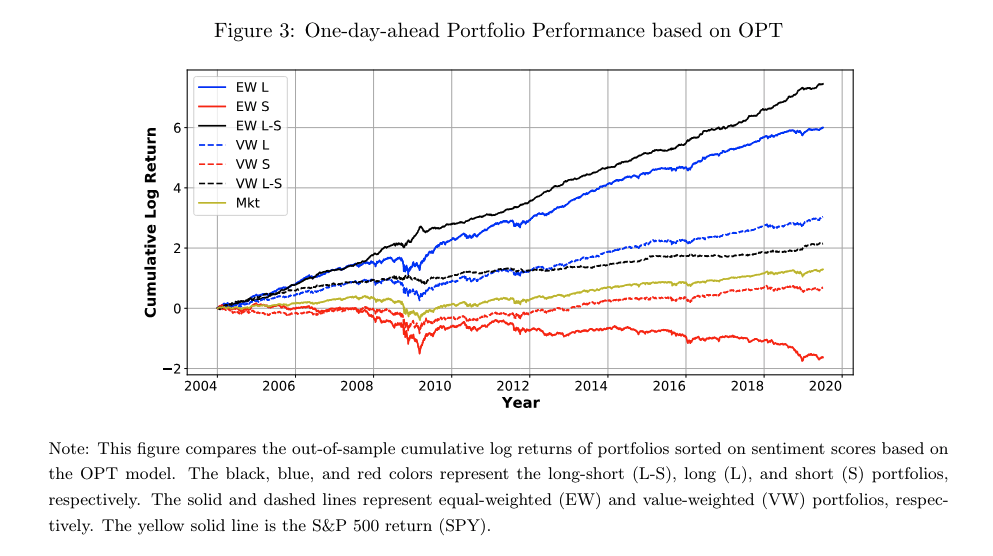
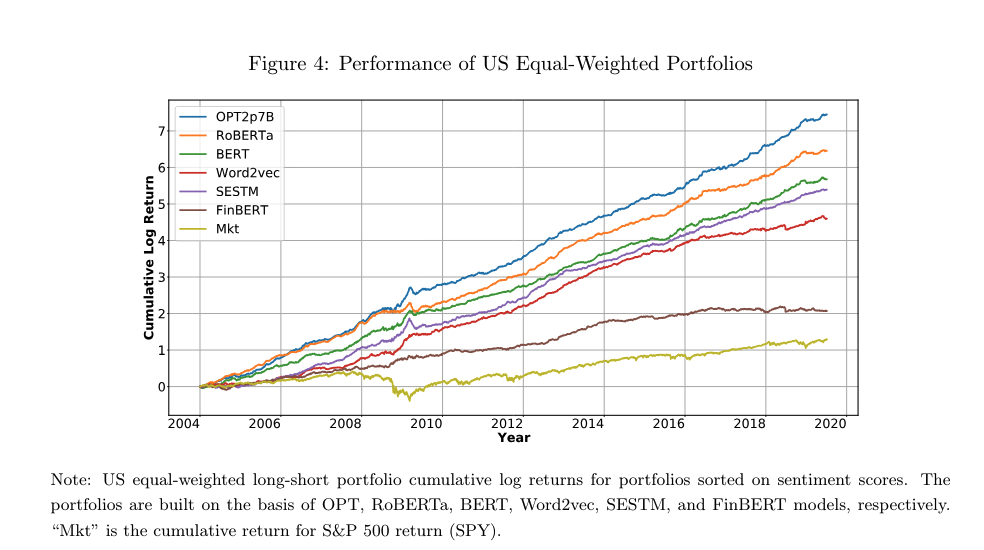
Personally, I feel this paper is more in line with the prior literature on BERT, while they are not making use of GPT’s conversational abilities.
Practical Advise
When using generative LLMs in practice, several key considerations emerge.
- Choice of model
- Most papers use GPT-3.5 or GPT-3.5 Turbo
- Choice of model parameters and system prompt
- Greatly depends on the context
- Kim et al. (2023a):
max_token=none, temperature=0.5, top_p=1, presence_penalty=0, frequency_penalty=0
- Input length exceed token limit
- Divide input text into chunks, then combine the responses of all chunks
- If the output is narrative, then concatenate the outputs of each input chunk as the final output (Kim et al., 2023)
- If the output is in number (score), then take the average value (Jha et al., 2023)
- Truncate input text by the token limit
- Keep the initial tokens within the limit (Chen et al., 2022)
- Pre-process input text to reduce its length
- Using BART (Bai et al., 2023)
- Divide input text into chunks, then combine the responses of all chunks
- Consistency and replicability
- Make the generations as deterministic as possible: set
temperature=0ortop_n=0 - Re-run the analysis for multiple times (at least for a small sample) to see how much the responses vary (Eisfeldt et al., 2023, Kim et al., 2023a)
- Be transparent in your model, parameters, prompt design, and always backup the raw prompts and completions
- Make the generations as deterministic as possible: set
That’s all I have for this post. If you are also interested in applying NLP techniques to finance research, feel free to check out my other posts.
In one of my earlier posts, I also discuss how ChatGPT change my workflow, if you are interesting, check it out here.
Thanks for reading, and see you next time!
Reference
- Bai, John (Jianqiu), Nicole M. Boyson, Yi Cao, Miao Liu, and Chi Wan, 2023, Executives vs. Chatbots: Unmasking Insights through Human-AI Differences in Earnings Conference Q&A. Working paper.
- Chen, Yifei, Bryan T. Kelly, and Dacheng Xiu, 2022, Expected Returns and Large Language Models. Working paper.
- Eisfeldt, Andrea L, Gregor Schubert, and Miao Ben Zhang, 2023, Generative AI and Firm Values. Working paper.
- Jha, Manish, Jialin Qian, Michael Weber, and Baozhong Yang, 2023, ChatGPT and Corporate Policies. Working paper.
- Kim, Alex G., Maximilian Muhn, and Valeri V. Nikolaev, 2023a, Bloated Disclosures: Can ChatGPT Help Investors Process Information? Working paper.
- Kim, Alex G., Maximilian Muhn, and Valeri V. Nikolaev, 2023b, From Transcripts to Insights: Uncovering Corporate Risks Using Generative AI. Working paper.