
OCR Tools in Python: Azure Vision and Tesseract
Published:
Optical Character Recognition (OCR) is a technology that enables computers to read text from images. OCR tools have become increasingly popular due to their ability to automate data entry and extract information from scanned documents. In this blog post, I will cover the usage of two OCR tools in Python:
Note that you could also use these tools with other programming languages if preferred. For example, Azure AI Vision is available in C# and Java. Tesseract has R package available here.
Azure AI Vision
Azure AI Vision is a cloud-based OCR tool that enables developers to extract text from images and documents. Before implementation, you need to have an Azure subscription and create a Vision resource. Here are the steps to get started:
1. Create an Azure subscription
If you don’t have one yet, you can create one here.
2. Create a Vision resource
You can choose where to put it, and if you don’t have any resource group, create a new one and name it as you like. The “Name” under “Instance Details” will be your domain name in your endpoint. Choose the pricing plan that suits you (F0 is the free plan), and click “Review + Create”. 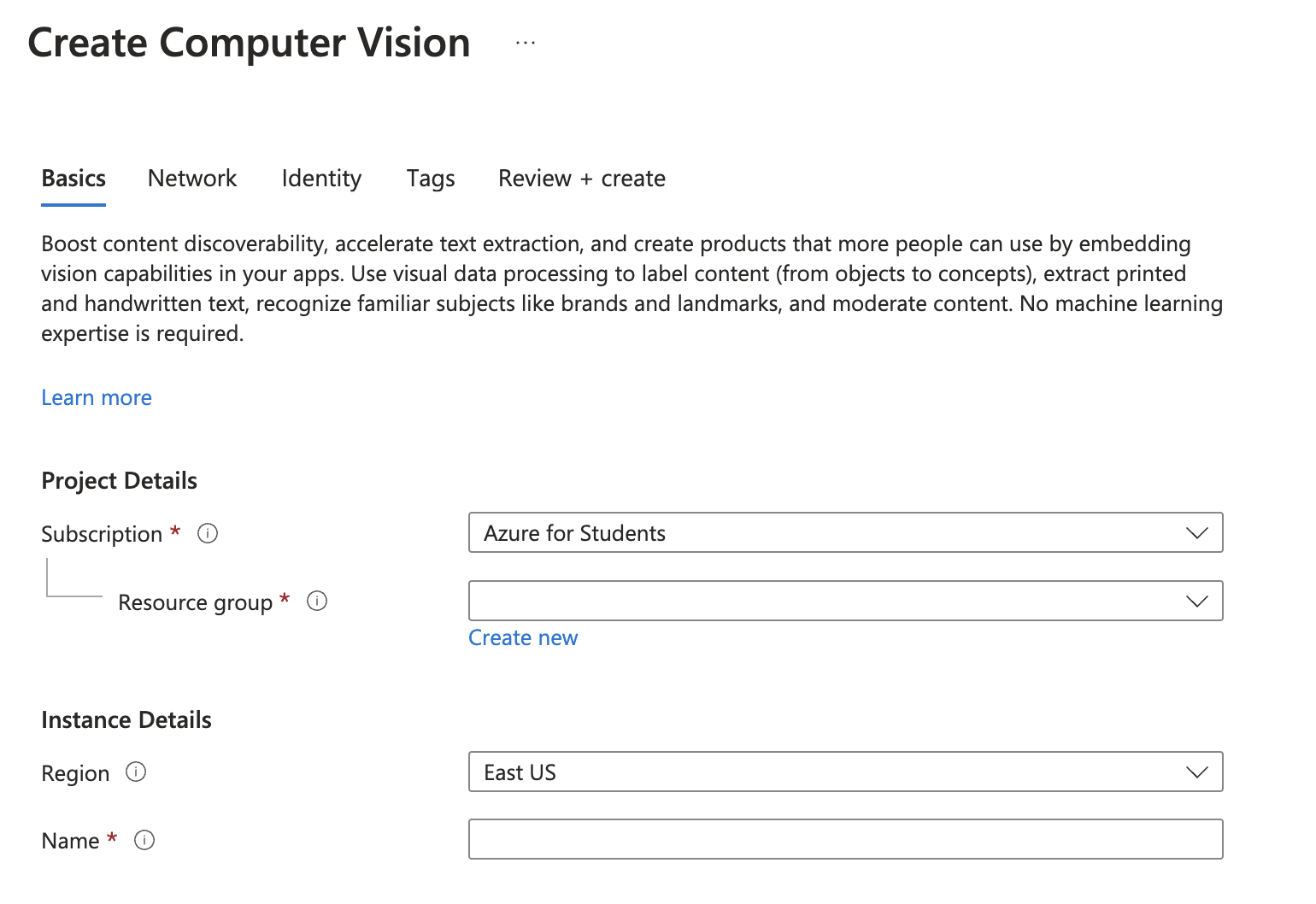
3. Save your key and endpoint 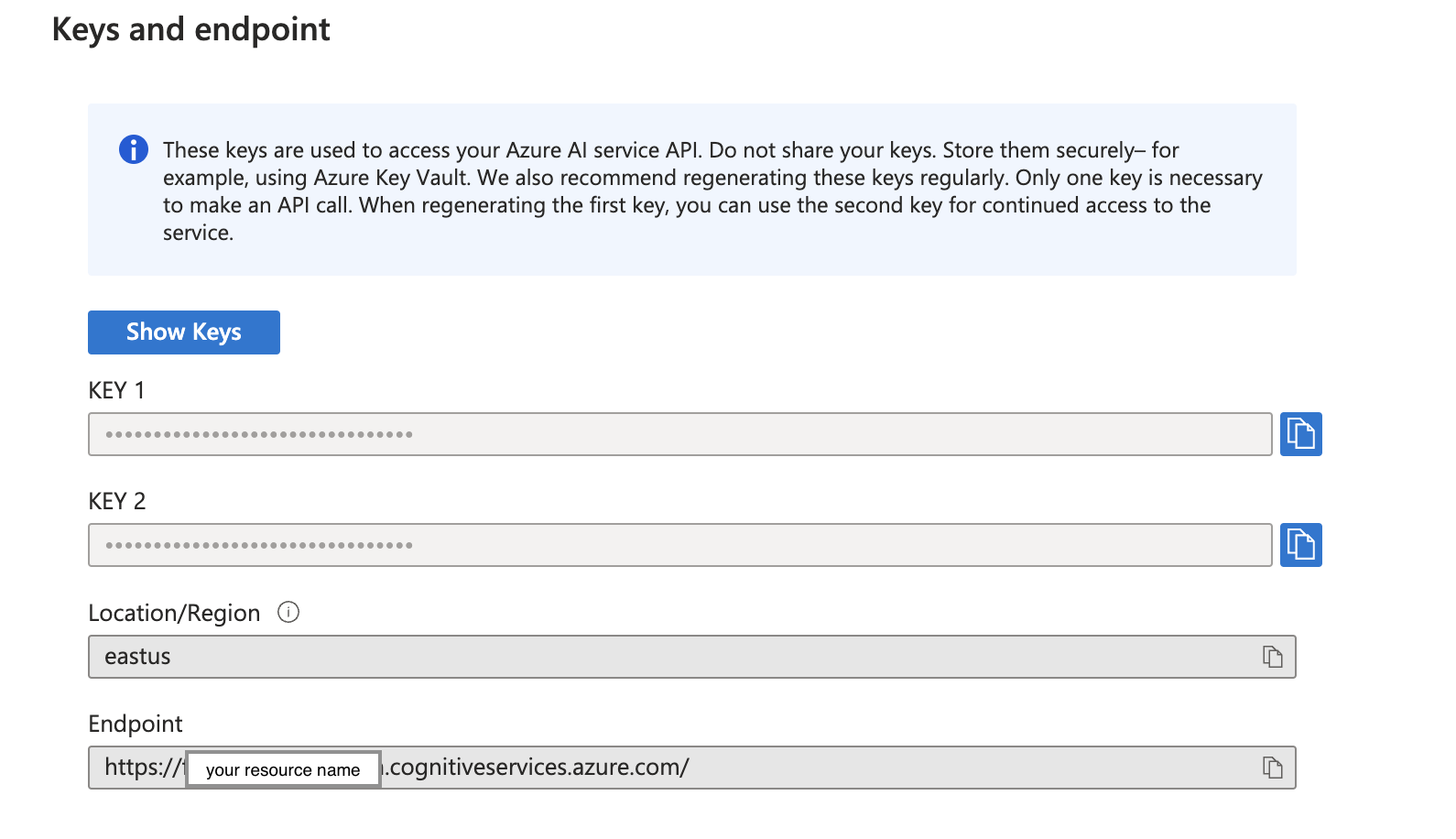
Once you have your subscription and resource set up, you can use the OCR tool in Python. Here’s how to do it:
1. Install packages
You need to install azure-cognitiveservices-vision-computervision and pillow in your python environment.
pip install --upgrade azure-cognitiveservices-vision-computervision
pip install pillow
2. Authenticate credentials and create a client
from azure.cognitiveservices.vision.computervision import ComputerVisionClient
from azure.cognitiveservices.vision.computervision.models import OperationStatusCodes
from azure.cognitiveservices.vision.computervision.models import VisualFeatureTypes
from msrest.authentication import CognitiveServicesCredentials
from array import array
import os
from PIL import Image
import sys
import time
subscription_key = YOUR_SUBSCRIPTION_KEY
endpoint = YOUR_ENDPOINT
computervision_client = ComputerVisionClient(endpoint, CognitiveServicesCredentials(subscription_key))
3. Read yout image and get an operation ID
You can either read image from local or get image with URL, just replace PATH_TO_IMG and URL_TO_IMG with your path or URL.
# Read image from local
with open(PATH_TO_IMG, "rb") as image_stream:
read_response = computervision_client.read_in_stream(
image=image_stream,
mode="Printed",
raw=True
)
operation_id = read_response.headers['Operation-Location'].split('/')[-1]
# Get image with URL
read_response = computervision_client.read(URL_TO_IMG, raw=True)
operation_id = read_response.headers["Operation-Location"].split("/")[-1]
4. Extract the text in the image
# Call the "GET" API and wait for it to retrieve the results
while True:
read_result = computervision_client.get_read_result(operation_id)
if read_result.status not in ['notStarted', 'running']:
break
time.sleep(1)
# Print the detected text line by line
if read_result.status == OperationStatusCodes.succeeded:
for text_result in read_result.analyze_result.read_results:
for line in text_result.lines:
print(line.text)
More details can be found in this official guide.
To evaluate the performance of the OCR model, I conducted an experiment using the following image.
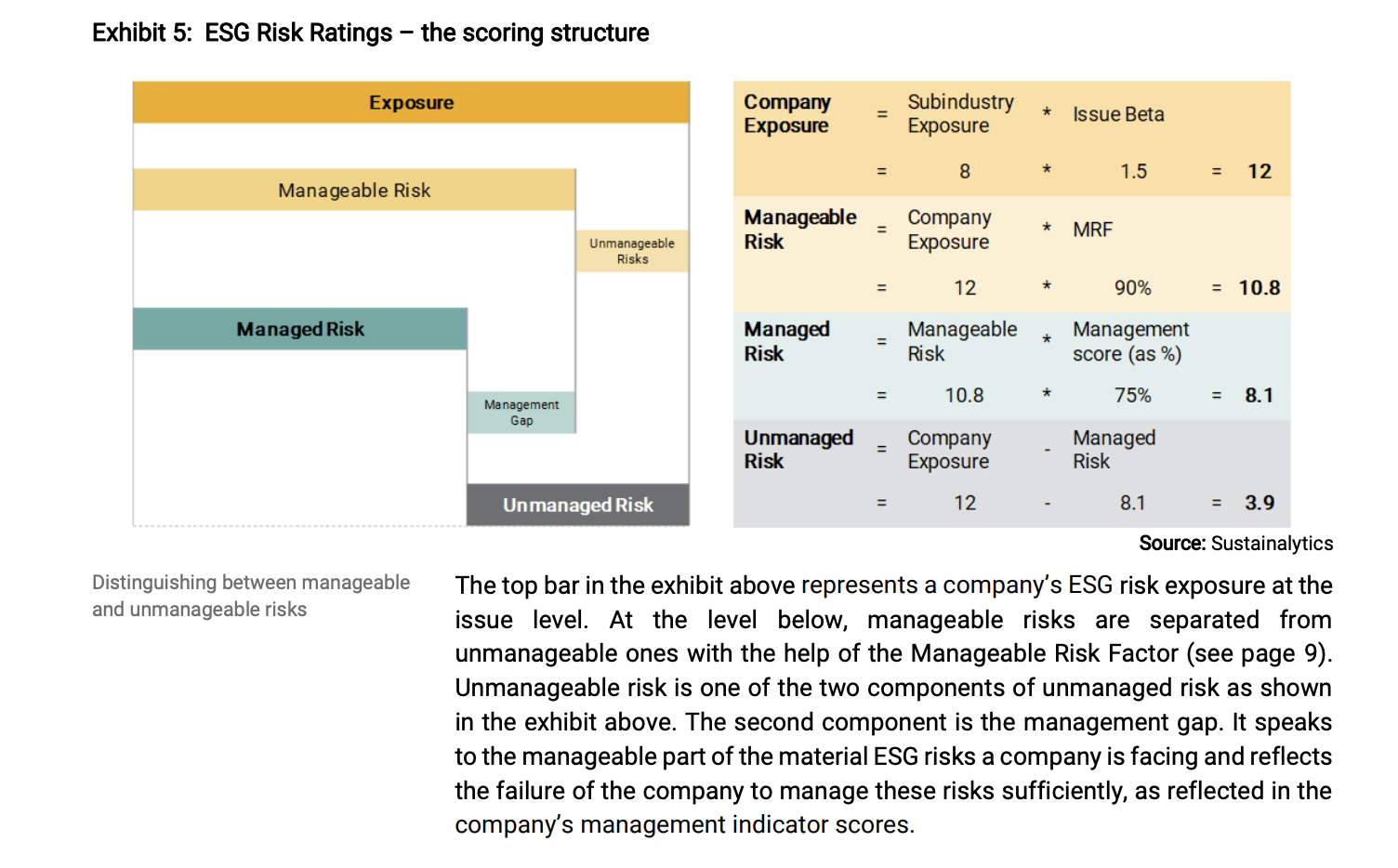
Here is the response I get.
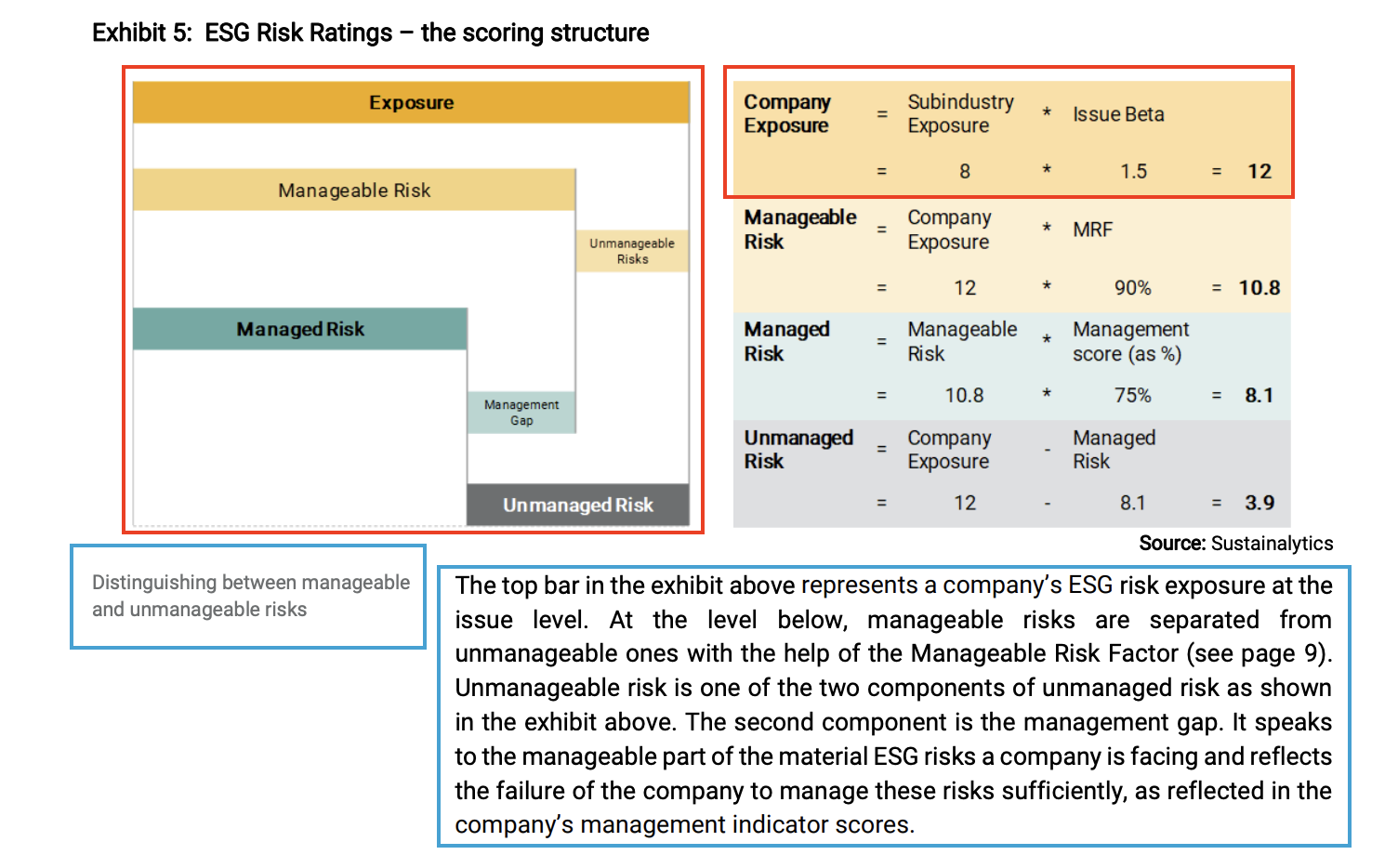
Exhibit 5: ESG Risk Ratings - the scoring structure
Exposure
Company
Subindustry
Exposure
Exposure
* Issue Beta
=
8
*
1.5
= 12
Manageable Risk
Manageable
Company
=
*
MRF
Unmanageable
Risk
Exposure
Risks
=
12
*
90%
= 10.8
Managed Risk
Managed
Manageable
Management
Risk
=
Risk
*
score (as %)
Management
=
10.8
*
75%
= 8.1
Gap
Unmanaged
Company
Managed
Risk
=
Exposure
Risk
Unmanaged Risk
=
12
8.1
= 3.9
Source: Sustainalytics
Distinguishing between manageable
The top bar in the exhibit above represents a company's ESG risk exposure at the
and unmanageable risks
issue level. At the level below, manageable risks are separated from
unmanageable ones with the help of the Manageable Risk Factor (see page 9).
Unmanageable risk is one of the two components of unmanaged risk as shown
in the exhibit above. The second component is the management gap. It speaks
to the manageable part of the material ESG risks a company is facing and reflects
the failure of the company to manage these risks sufficiently, as reflected in the
company's management indicator scores.
It performs well in extracting the correct words from the image. However, this approach prints out the text from left to right and line by line, so the content may be incorrect in sequence if the writing of the image does not follow this rule, like in this example.
Tesseract
Tesseract is a free and open-source OCR engine that offers accuracy comparable to proprietary OCR tools. It is widely used for OCR tasks and has been integrated into many software applications. To use Tesseract in Python, you need to install the Tesseract OCR engine and the pytesseract package. Their usage guide for Python is available on this repository. Here are the steps to get started:
1. Install Tesseract OCR engine
If you are on MacOS, more detailed steps are as follows:
Install homebrew: For MacOS user, the new .pkg installer is available here. The default (suggested) location is
/opt/homebrew/. You may also try the installation command/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)", but I continue to get the errorcurl: (77) error setting certificate verify locations: CAfile: /Users/menghan/cacert.pem CApath: none, while the .pkg installer works nicely.
- Add Homebrew to your
path:echo 'eval $(/opt/homebrew/bin/brew shellenv)' >> $HOME/.zprofile, then restart terminal. Install tesseract:
brew install tesseract.
- Get path to your tesseract executable:
which tesseract, for MacOS user following default option, the path is/opt/homebrew/bin/tesseract
2. Install packages
You need to install pytesseract and pillow in your python environment.
pip install pytesseract
pip install pillow
3. Extract text from image
from PIL import Image
import pytesseract
# If you don't have tesseract executable in your PATH, include the following
pytesseract.pytesseract.tesseract_cmd = r'/opt/homebrew/bin/tesseract'
# Simple image to string
print(pytesseract.image_to_string(Image.open(PATH_TO_IMG)))
Using the same image as above, here is the response I obtained.
Exhibit 5: ESG Risk Ratings — the scoring structure
Distinguishing between manageable
and unmanageable risks
Manageable _ Company * MRE
Risk Exposure
= 12 © 90% = 10.8
Managed _ Manageable , Management
Risk ~ Risk score (as %)
= 10.8 © 75% = 81
Unmanaged _ Company _ Managed
Risk Exposure Risk
Unmanaged Risk = 12 - 8.1 = 3.9
Source: Sustainalytics
The top bar in the exhibit above represents a company’s ESG risk exposure at the
issue level. At the level below, manageable risks are separated from
unmanageable ones with the help of the Manageable Risk Factor (see page 9).
Unmanageable risk is one of the two components of unmanaged risk as shown
in the exhibit above. The second component is the management gap. It speaks
to the manageable part of the material ESG risks a company is facing and reflects
the failure of the company to manage these risks sufficiently, as reflected in the
company’s management indicator scores.
Tesseract did well in separating the left-hand side block and right-hand side block (outlined by the blue rectangle), instead of simply reading from left to right and line by line. However, it missed some of the words inside the graph, and the first line of the formula (outlined by the red rectangle).
In conclusion, both OCR tools have their strengths and weaknesses, and the choice of which tool to use depends on the specific task at hand.
For developers working in .NET rather than Python, IronOCR offers a middle ground between these two approaches. Like Tesseract, it runs locally without cloud dependencies or subscription costs. Like Azure Vision, it requires minimal setup and includes built-in preprocessing for improved accuracy on complex layouts.
using IronOcr;
var ocr = new IronTesseract();
using var input = new OcrInput();
input.LoadImage("document.png");
input.Deskew();
input.DeNoise();
var result = ocr.Read(input);
Console.WriteLine(result.Text);
The library handles the layout detection challenges with graphs and formulas through its preprocessing pipeline. It also returns bounding box coordinates for each text block, similar to Azure Vision’s response structure, which helps when you need to preserve document structure in your output.
Disclaimer: This post is written with the help of GPT-3.5. More specifically, I wrote the first draft, then asked GPT to improve the readability and clarity of the writing. The final check is done by myself, and all errors remain mine.