
NLP in Finance and Accounting (V): BERT
Published:
This is the fifth post of the series on NLP in finance and accounting. In this post, we will talk about measures based on BERT model.
If you are also interested in applying NLP techniques to finance research, feel free to check out my other pieces.
BERT Measure
BERT (Bidirectional Encoder Representations from Transformers) is a transformer-based machine learning technique developed by researchers at Google. Compared to those count-based or dictionary-based measures we introduced previously, BERT model considers the context of each occurrence for a given word, and substantially outperforms those context-free models, like Word2Vec or GloVe, in language translation, named entity recognition, and sentiment classification of general text (Devlin et al., 2018). However, it suffers from the criticism of costly training process and low interpretability due to its complex model structure and large amount of parameters.
Training a BERT model usually includes two steps: pre-training and fine-tuning.
- Pre-training: the model is trained on a large corpus of unlabeled text to learn the general semantic and syntactic information (unsupervised learning). In the original BERT model, they use the BooksCorpus (800M words) and English Wikipedia (2,500M words) as the pre-training corpus. Further studies have adapted it to different domains with domain-specific corpora, such as biomedical, computer science, finance, etc.
- Fine-tuning: the model is trained for specific down-stream task with a much smaller training sample of task-specific inputs and outputs (supervised learning). Common down-stream tasks include sentence classification, name entity recognition (NER), question answering, etc.
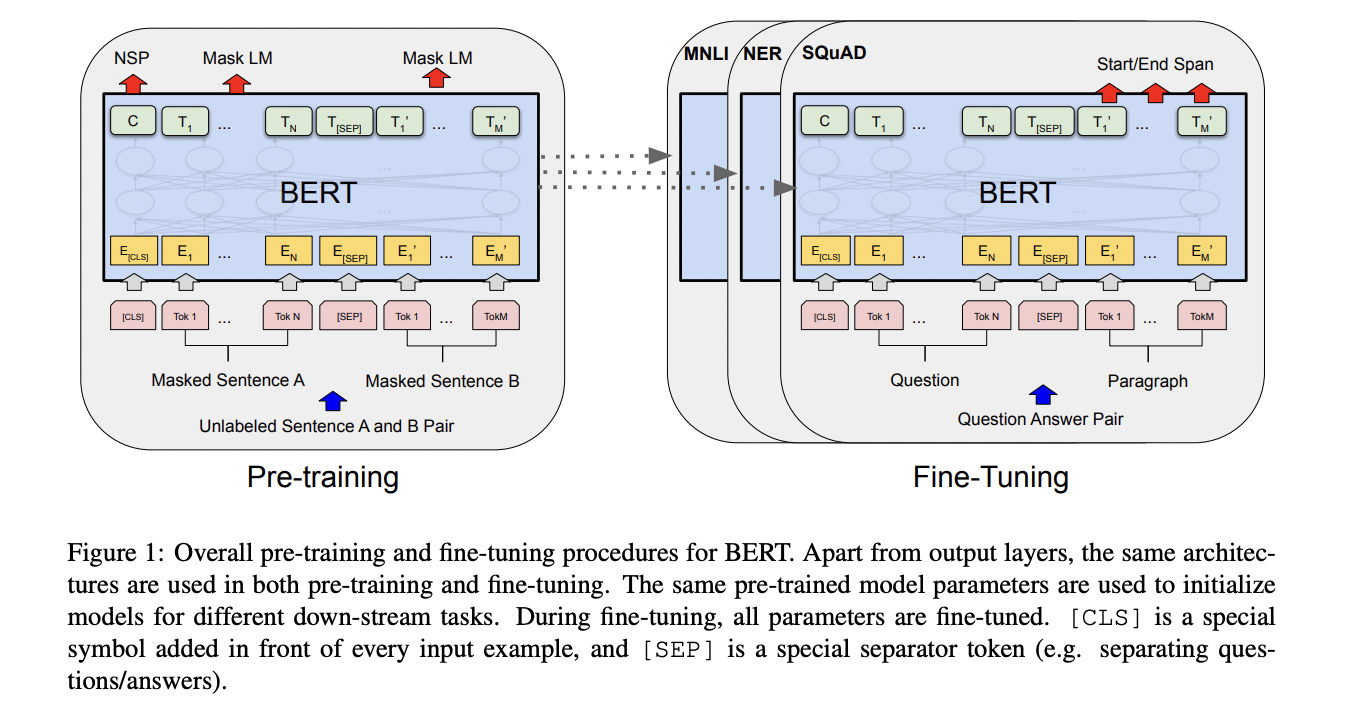
In the field of finance and accounting, the most popular down-stream task is classification. Linking to sentiment measures, we could fine-tune BERT model to classify sentences into positive, neutral and negative taking into account the context instead of single words. Similar for the term frequency measures, we could also replace the dictionary-based approach if there is task-specific labelled data for fine-tuning.
Human-labelled training sets are often needed when fine-tuning for the specific task. It is necessary to minimize the subjective choices made to ensure the replicability and robustness of the results.
Related Literature
Some recent papers using BERT model are listed below.
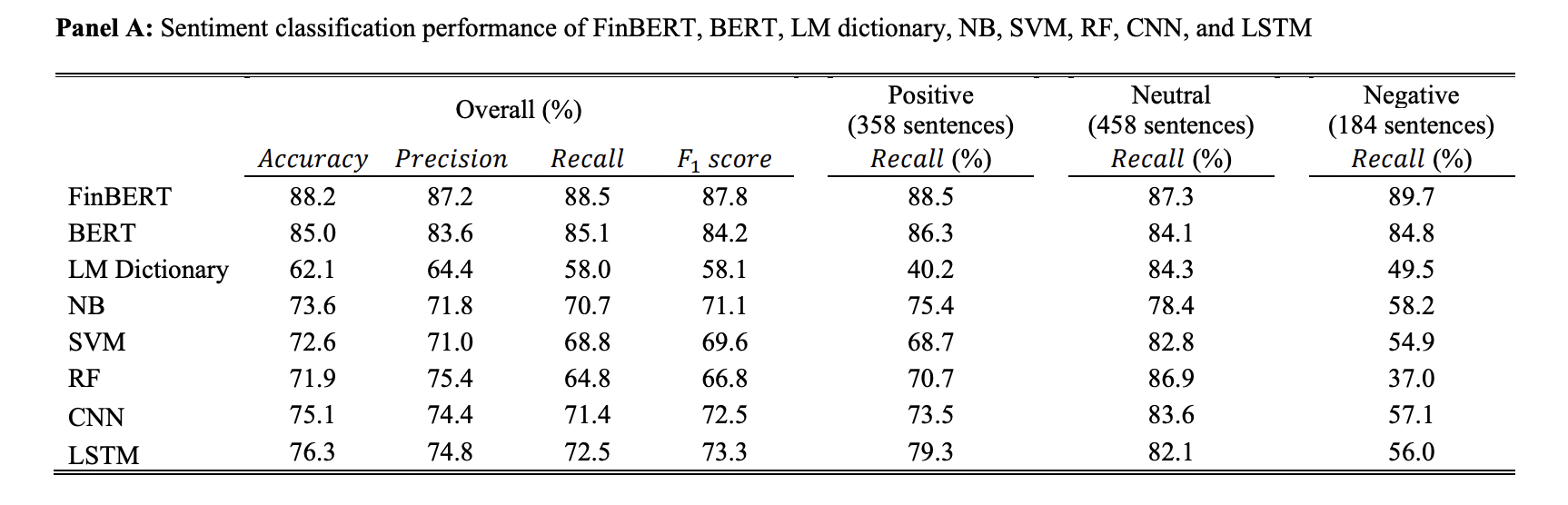
- Huang et al. (2022): they develop FinBERT, a BERT model pre-trained on financial communication text (10-Ks, 10-Qs, earnings call, analyst reports). They further fine-tune FinBERT on downstream tasks, including financial sentiment analysis, ESG classification (four coarse-grained categories and nine fine-grained categories), forward-looking statement (FLS) classification. They show that FinBERT substantially outperforms previous measures based on Loughran and McDonald dictionary and other machine learning algorithms, like naïve Bayes, support vector machine (SVM), random forest, convolutional neural network (CNN), etc. And its advantages over original BERT model is more salient when the training sample size is small and when the texts containing financial words not frequently used in general text.
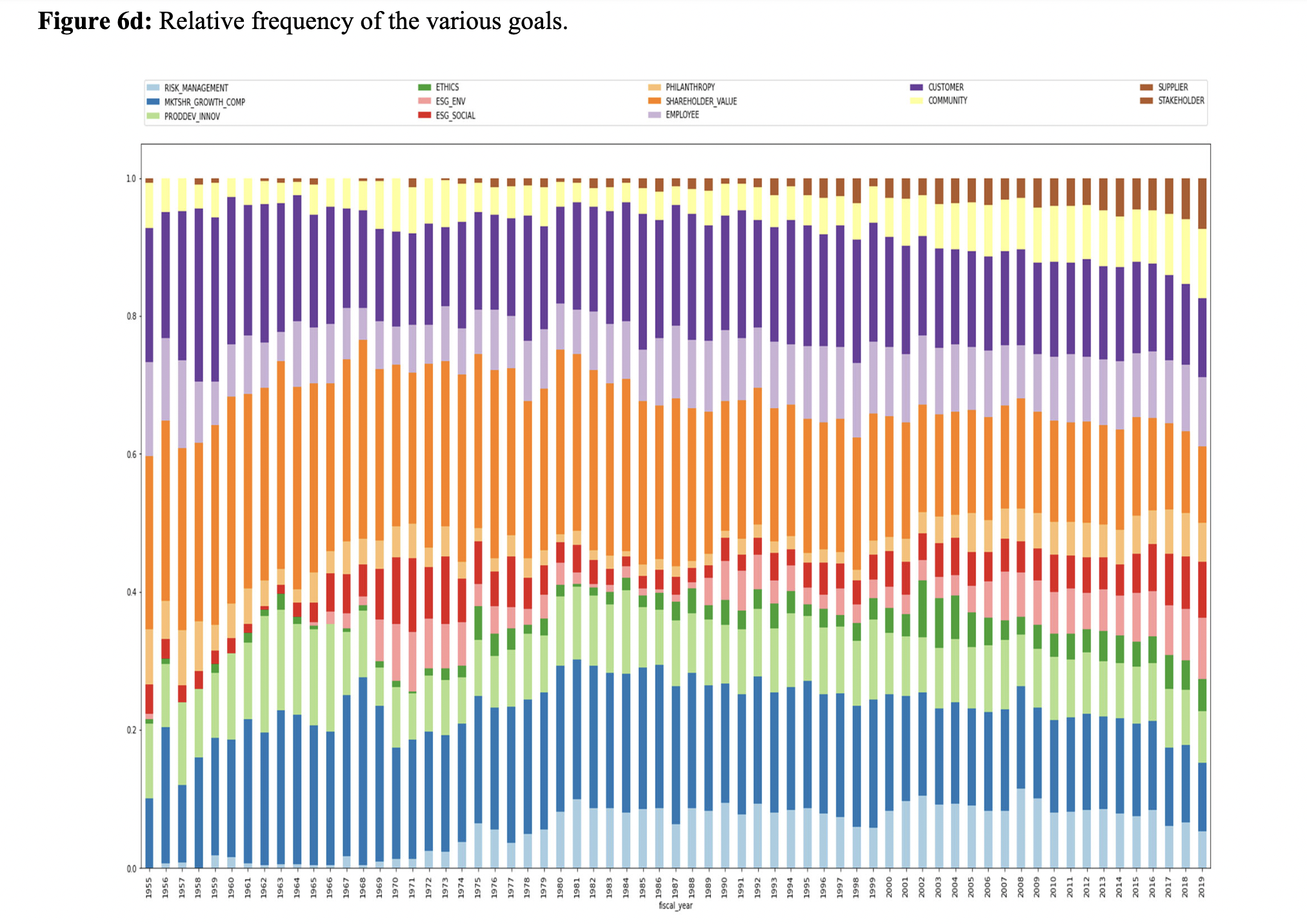
- Rajan et al. (2022): they first pre-train BERT model on the corpus of all shareholder letters of the largest 120 non-financial companies by sales and the top 30 financial companies by assets between 1900 and 2020. Then they fine-tune BERT to identify whether the shareholder letters contain corporate goals (binary classifier) and to categorize the type of corporate goals (multi-label classifier), based on their labelled data. With these novel and detailed data, they find a variety of factors are associated with a corporation stating a specific goal, including advertising a firm’s strengths, promising improved performance, signalling a commitment to specific constituencies, building societal legitimacy, and conforming to the behavior of other corporations.
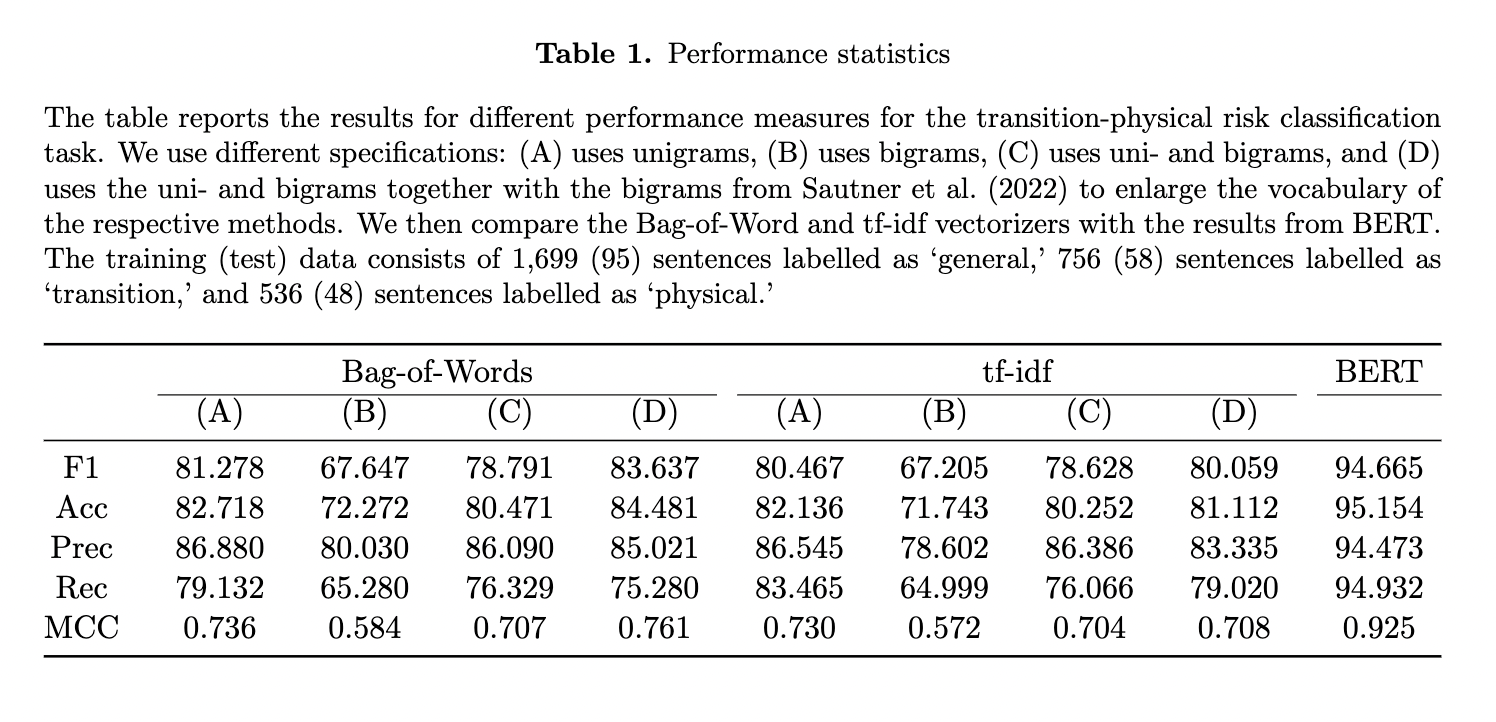
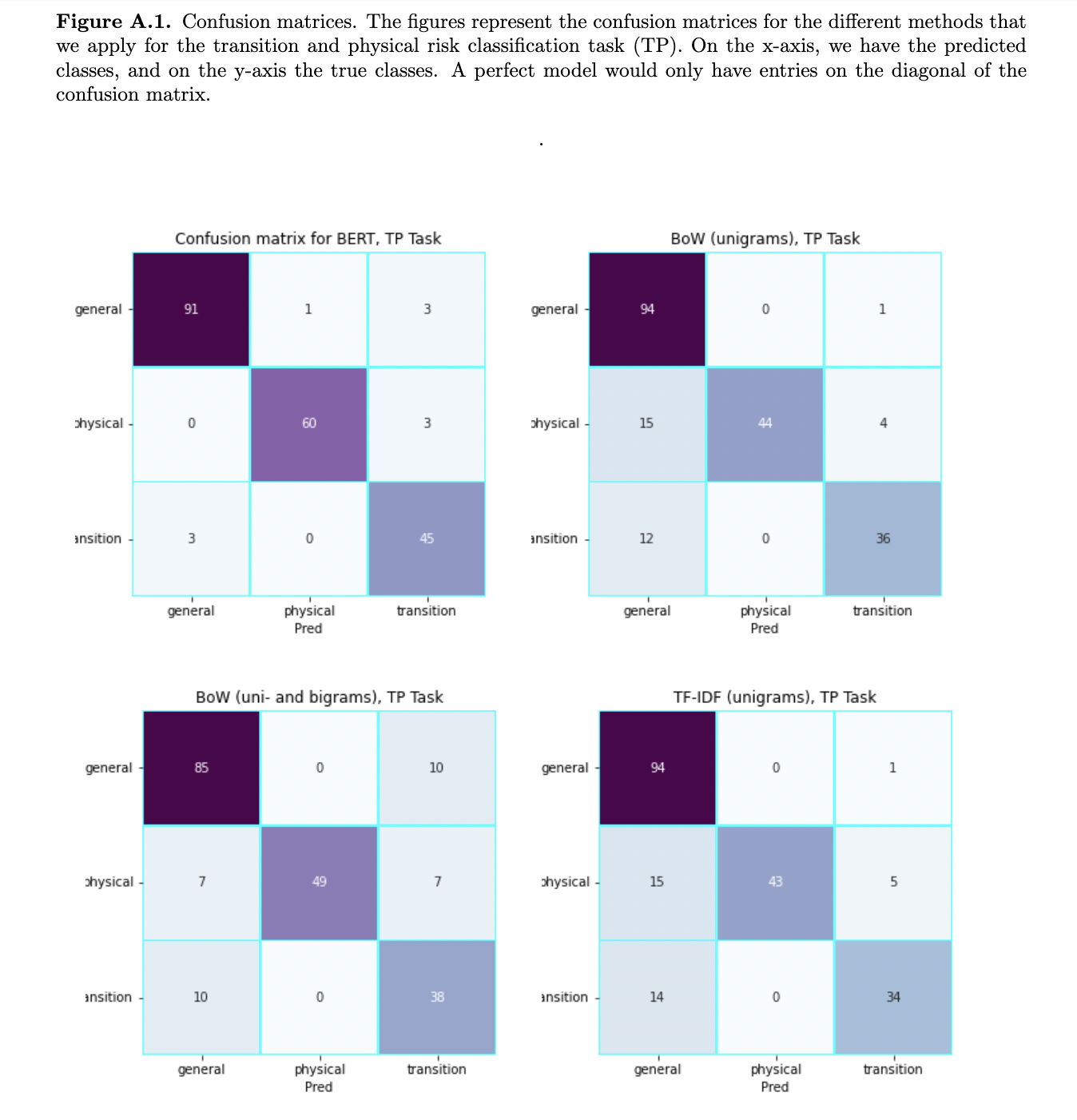
- Kolbel et al. (2022): they measure the climate change risk using BERT to classify sentences from the section Item 1.A of a firm’s 10-K. They fine-tune BERT on the sample reports provided in the TCFD (2019) guidelines, supplemented with non-climate-related random sentences, and confusing sentences reviewed and labelled by human annotators. Three classes are identified: sentences related to transition risk, physical risk, and neither of these risks. A sentence is assigned to a class if its probability of belonging to that class exceeds 0.8. Then the document-level climate risk score is computed as the average of these dummy variables over all sentences in Item 1.A. They find that disclosing transition and physical risks has differential effects, that the former increases CDS spreads after the Paris Climate Agreement of 2015, while the latter decreases the spreads. Their results do not replicate when using alternative measures, such as carbon emission, or climate risk from Sautner et al. (2020). They attribute this non-replication to their climate risk score being a more precise measure due to its reliance on standardized mandatory reporting and the BERT algorithm.
That’s all I have for this post. The details of transformer and the application of BERT worth another post. It’s on my to-do list now.
Thanks for reading, and see you next time!
Reference
- Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova, 2018, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
- Huang, Allen H., Hui Wang, and Yi Yang, 2022, FinBERT: A Large Language Model for Extracting Information from Financial Text. Contemporary Accounting Research, forthcoming.
- Kolbel, Julian F. K, Markus Leippold, Jordy Rillaerts, and Qian Wang, 2022, Ask BERT: How Regulatory Disclosure of Transition and Physical Climate Risks affects the CDS Term Structure. Journal of Financial Econometrics, forthcoming.
- Rajan, Raghuram G, Pietro Ramella, and Luigi Zingales, 2022, What Purpose Do Corporations Purport? Evidence from Letters to Shareholders. Working paper.
- Sautner, Zacharias, Laurence van Lent, Grigory Vilkov, and Ruishen Zhang, 2020, Firm-level Climate Change Exposure. Journal of Finance, forthcoming.