
NLP in Finance and Accounting (IV): Readability Measure
Published:
This is the fourth post of the series on NLP in finance and accounting. In this post, we will talk about readability measures.
Readability Measure
Readability measures aim to quantify the readers’ ability to understand the (financial) documents, or more generally, the information complexity. In linguistics, Fog index was developed by Robert Gunning in 1952 to measure readability. The index estimates the years of formal education a person needs to understand the text on the first reading. For instance, a fog index of 16 indicates the reader need 16 years of education, namely a college degree (around 22 years old), to understand the content on its first reading.
In finance and accounting literature, research on readability has a long history, as summarized by Jones & Shoemaker (1994). But the sample sizes of these early studies are very small. Li (2008) is the first paper to examine the readability of financial documents (annual reports) with a meaningful sample size. Follow-up studies refine the measurement to suit financial document, and explore it in various contents. Common readability measures used in finance and accounting include Fog index, document length (total words), file size, Bog index, etc. Loughran & Mcdonald (2016) summarized research on readability in section 2.2.
Related Literature
Some studies using different measures for readability are listed below.
- Li (2008): it measured the readability of 10-Ks using the Fog index and the length of the document. Specifically, the Fog index is positively related to average word per sentence and the percentage of complex words (those with 3 syllables or more), while the document length is the natural logarithm of the number of words in the document.
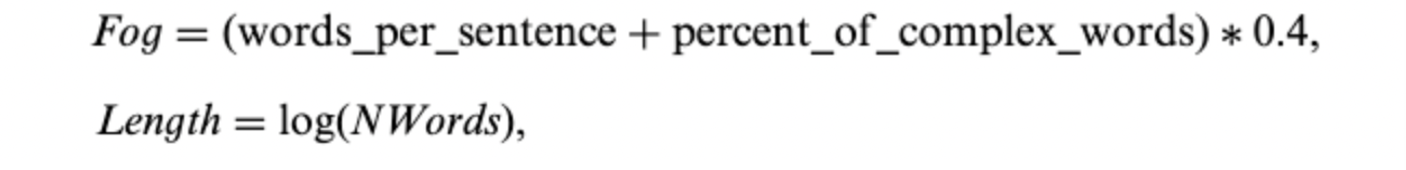
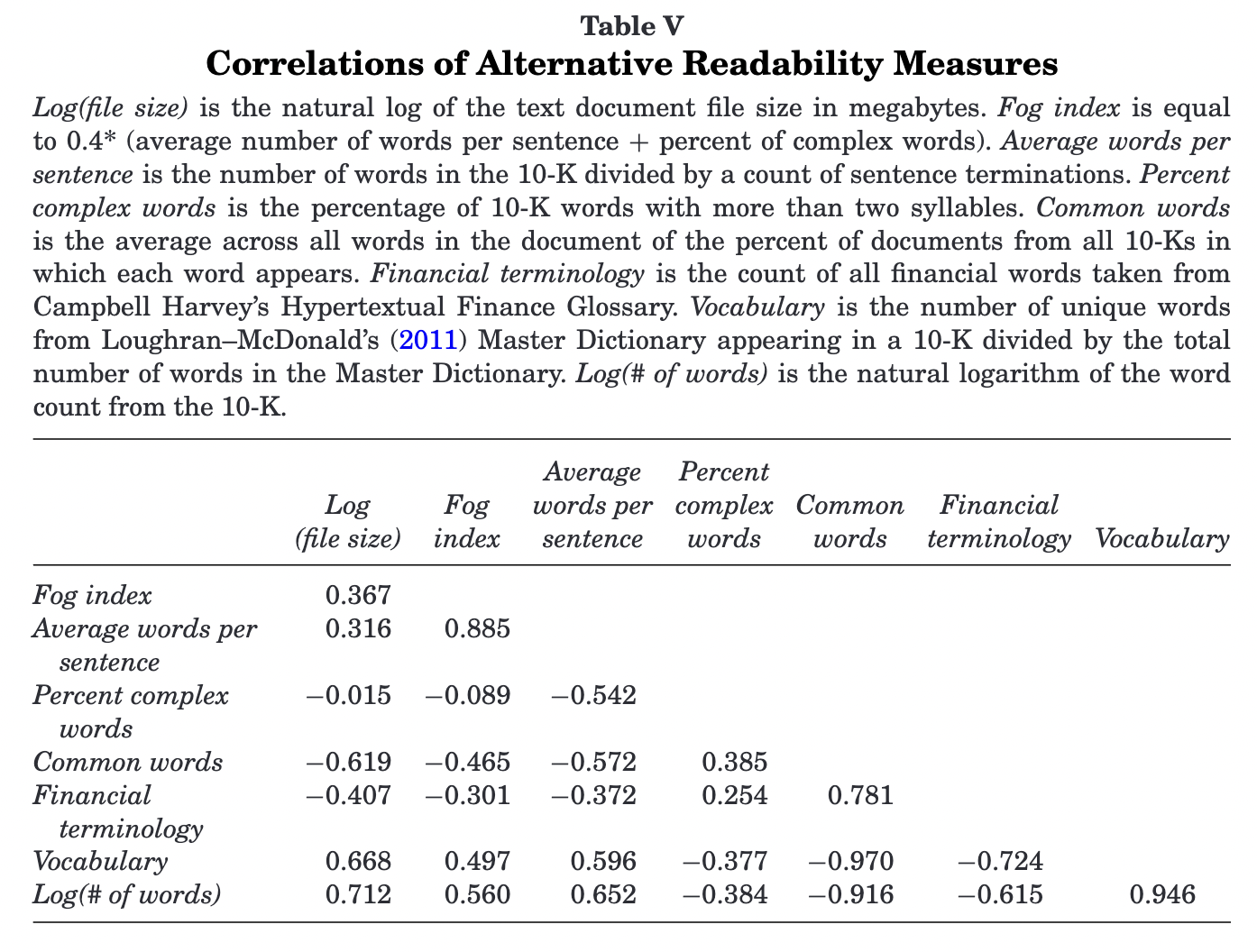
- Loughran & Mcdonald (2014): it argues Fox index may not be a proper measure in finance and accounting domain. For instance, the most common complex words in business document, like financial, company, operations, management, employees, customers, are easily understood by investors. And the two components of Fog index (sentence length and percentage of complex words) are negatively correlated in their sample, inconsistent with the presumed effect. They suggest using the natural log of gross 10-K file size as a proxy for readability, as it does not require document parsing, facilitates replication, and is correlated with alternative readability constructs. However, this measure is not perfect. Leuz and Schrand (2009) find that firms increase 10-K length to improve firm-specific transparency after Enron scandal, which lowered their cost of capital. Besides, it cannot separate the fundamental complexity of the firm’s business from its language complexity of 10-K, though a potential remedy will be to add controls of fundamental complexity, e.g. firm size, number of business segments, HHI based on segment revenue, etc.
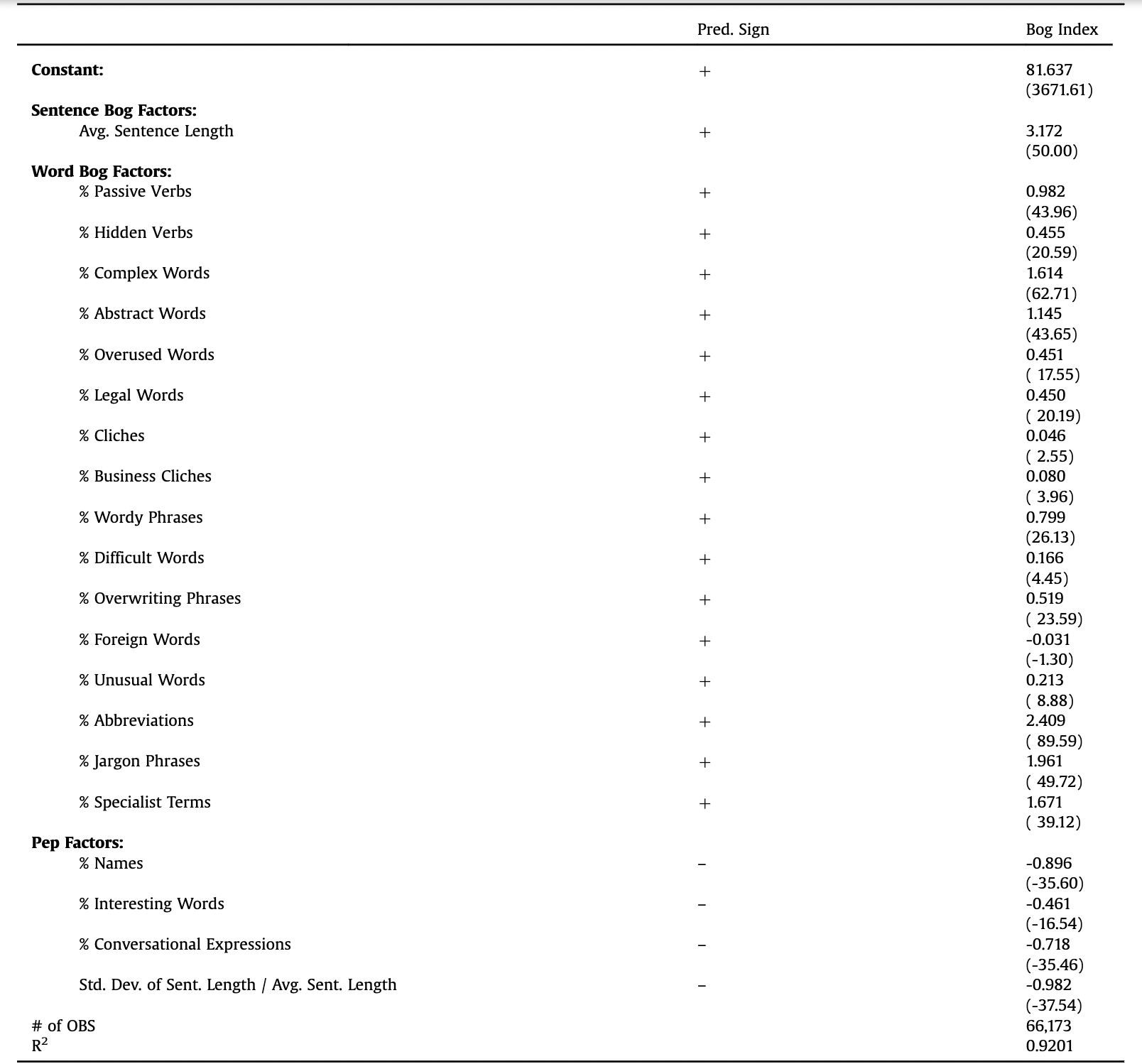
- Bonsall et al. (2017): they agree with Loughran & Mcdonald (2014) that Fog index could be misleading in the context of financial reporting, but also argue that a vast amount of the variation in 10-K file size over time is driven by the inclusion of content unrelated to the underlying text (e.g., HTML, XML, PDFs). They propose a new measure, Bog index, computed as Sentence Bog plus Word Bog minus Pep. It summarizes the writing attributes provided by StyleWriter, a computational linguistics software program. A higher Bog Index equates to a less readable document.
- Sentence Bog: the squared average sentence length, scaled by a standard long sentence limit of 35 words per sentence.
- Word Bog: the sum of plain English style problems and word difficulty multiplied by 250 and divided by the number of words.
- Plain English style problems include passive verbs, hidden verbs, overwriting, legal terms, clichés, abstract words, and wordy phrases, as listed in SEC Plain English Handbook. Higher scores indicate more problems and lower readability.
- Word difficulty measured by a proprietary list of over 200,000 words based on familiarity and assesses penalties between zero and four points based on a combination of the word’s familiarity and precision. Higher scores indicate higher difficulty.
- Pep: the sum of good writing (interesting items such as names and interesting words) multiplied by 25, and scaled by the number of words in the document plus sentence variety (the standard deviation of sentence length multiplied by ten and scaled by the average sentence length).

- Hwang & Kim (2017): it proposes a refined readability measure for annual reports of equity closed-end investment companies (CEFs). Similar to Bonsall et al., the measure is based on StyleWriter as well. More specifically, their baseline readability measure is defined as the occurrences of passive verbs, hidden verbs, legal words, overwriting, and wordy phrases, scaled by the number of sentences, multiply -10 to help interpret the coefficient estimates and make the measures positively related to readability.


That’s all I have for this post. If you are also interested in applying NLP techniques to finance research, feel free to check out other pieces.
Stay tuned to this series, see you next time!
Reference
- Bonsall, Samuel B., Andrew J. Leone, Brian P. Miller, and Kristina Rennekamp, 2017, A plain English measure of financial reporting readability. Journal of Accounting and Economics 63, 329–357.
- Hwang, Byoung-Hyoun, and Hugh Hoikwang Kim, 2017, It pays to write well. Journal of Financial Economics 124, 373–394.
- Li, Feng, 2008, Annual report readability, current earnings, and earnings persistence. Journal of Accounting and Economics 45, 221–247.
- Loughran, Tim, and Bill Mcdonald, 2014, Measuring Readability in Financial Disclosures, The Journal of Finance 69, 1643–1671.
- Loughran, Tim, and Bill Mcdonald, 2016, Textual Analysis in Accounting and Finance: A Survey. Journal of Accounting Research 54, 1187–1230.
- Wikipedia, Gunning fog index.