
NLP in Finance and Accounting (III): Sentiment Measure
Published:
This is the third post of the series on NLP in finance and accounting. In this post, we will talk about sentiment measures. There are two main approach to construct sentiment measures.
Dictionary-based Approach
Most of the existing studies use dictionary-based approach to identify word sentiment, and the most common measure for the sentiment of a document is the number of words associated with a particular sentiment category scaled by the total number of words in the document. Sometimes, this proportion is adjusted by IDF (inverse document frequency) to account for how unusual the word is. Under dictionary-based approach, the choice (or construction) of dictionary is the main subject decision that researchers need to make. Once it is done, we are back to word counts again. There are several dictionaries commonly-used in literature.
- Havard IV-4 positive and negative word lists: they are among the first readily available dictionary, though not created using financial text, many papers use them to measure sentiment in newspapers, earnings conference calls, press releases, etc. (Tetlock, 2007; Tetlock et al., 2008; Kothari et al., 2009; Hanley & Hoberg, 2010)
- Diction optimism and pessimism word lists: the optimism subcategories of praise, satisfaction and inspiration are usually pooled for a positive word list, while the pessimism subcategories of blame, hardship and denial are pooled for a negative word list. Sentiment measures using Diction is more common in accounting than finance (Davis et al., 2012; Davis & Tama-Sweet, 2012).
- Loughran & McDonald (2011) word lists: they document that almost three-fourths (73.8%) of the negative word counts according to the Harvard list are attributable to words that are typically not negative in a financial context. For instance, tax, cost, capital, board, liability, foreign, vice appear with great frequency in most of 10-Ks without revealing a negative sentiment. To address this issue, they create 6 different word lists with respect to positive, uncertainty, litigious, strong modal, and weak modal by examining word usage in a large sample of 10-Ks during 1994-2008 (available here). Most of the latter studies are built on LM word lists (Feldman et al., 2010; Dougal et al., 2012; Mayew & Venkatachalam, 2012; Liu & McConnell, 2013; Garcia, 2013; Chen et al., 2014; Allee & DeAngelis, 2015).
It is worth noted that negative sentiment tends to convey more information than positive sentiment or net sentiment scores, as negative words are usually less unambiguous compared to positive words. Namely, it is common for management to use positive words when making a negative statement, but rarely the other way around.
Machine Learning Approach
Alternatively, some studies use supervised machine learning like Naive Bayes to train classification model, when there is no readily available dictionary. Such approach is applicable to classification task in general, not necessarily sentiment. However, it requires a manually-classified training dataset, which could be labor-intensive and suffer from subjectivity.
- Antweiler & Frank (2004): they classify messages from Yahoo! Finance and Raging Bull to three types, buy, hold, sell, using a Naive Bayes model trained on 1000 messages. They also consider SVM (Support Vector Machine) for robustness check.
- Li (2010): a Naive Bayes model was trained on 30000 sentences of randomly selected FLS (forward-looking statements) from MD&A section along two dimensions, tone (positive, negative, neutral, uncertain) and content (revenues, cost, profits, operations, liquidity, investing, financing, litigation, employees, regulation, accounting, other).
- Huang et al. (2014): they classify analysts opinions into three categories, positive, negative and neutral, using Naive Bayes classifier trained on 10000 manually-classified sentences in analyst reports. The overall opinion of a report is measured by the percentage of positive sentence minus the percentage of negative sentence.
- Buehlmaier & Whited (2018): they model the probability of being financially constrained as a function of word counts in MD&A using Naive Bayes algorithm. Three training samples are used to construct three measures respectively: (1) Factiva sample for general financial constraints, (2) equity sample using keywords from delay list and equity-focused list (Hoberg & Maksimovic, 2015) for investment delays due to issuing equity, (3) debt sample using keywords from delay list and debt-focused list (Hoberg & Maksimovic, 2015) for investment delays due to issuing debt.
The survey paper by Kearney & Liu (2014) reviews studies on textual sentiment published prior to 2013. It is generally agreed that textual sentiment has some predictive power on future earnings and stock return. They provide a detailed summary table of previous literature.
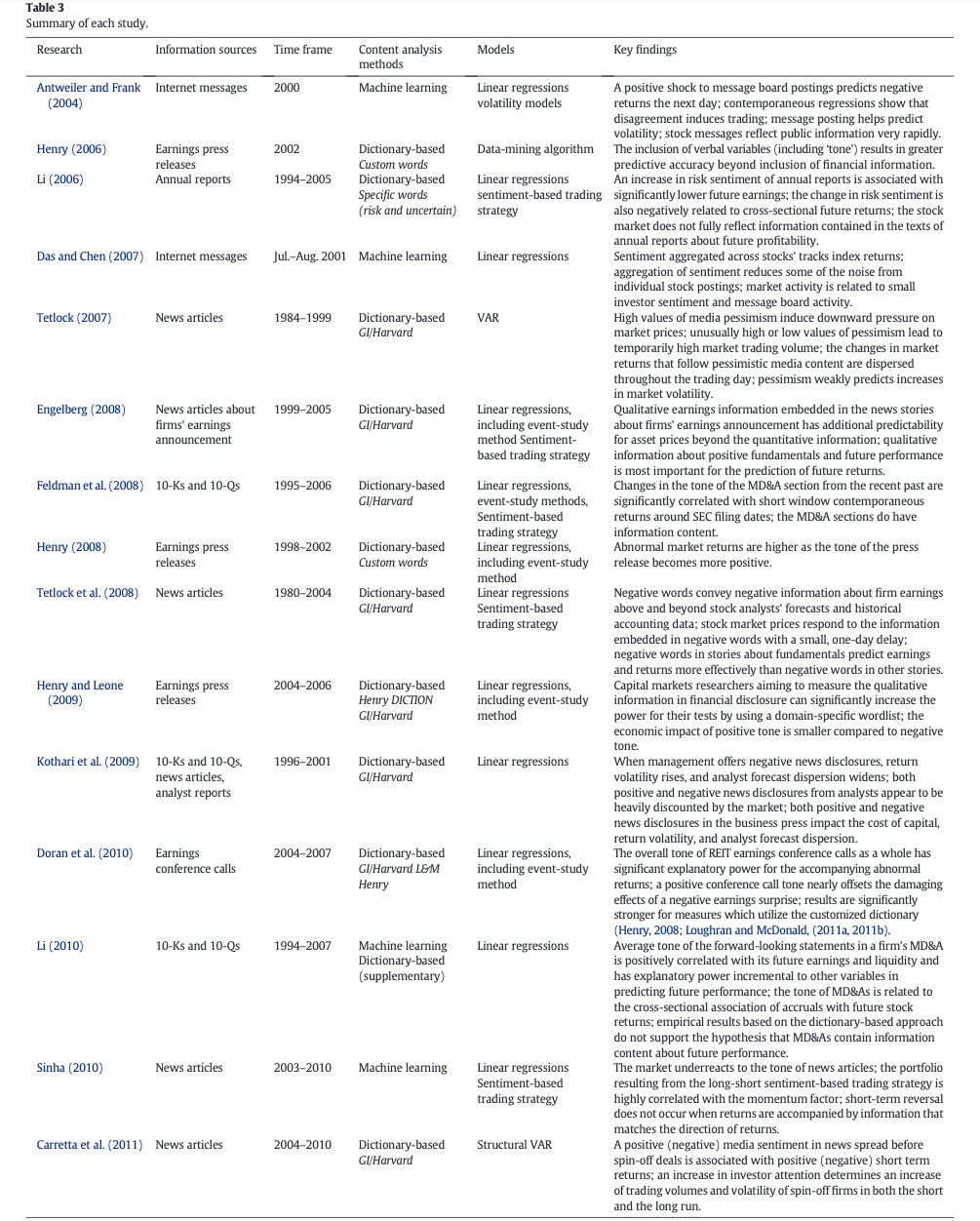
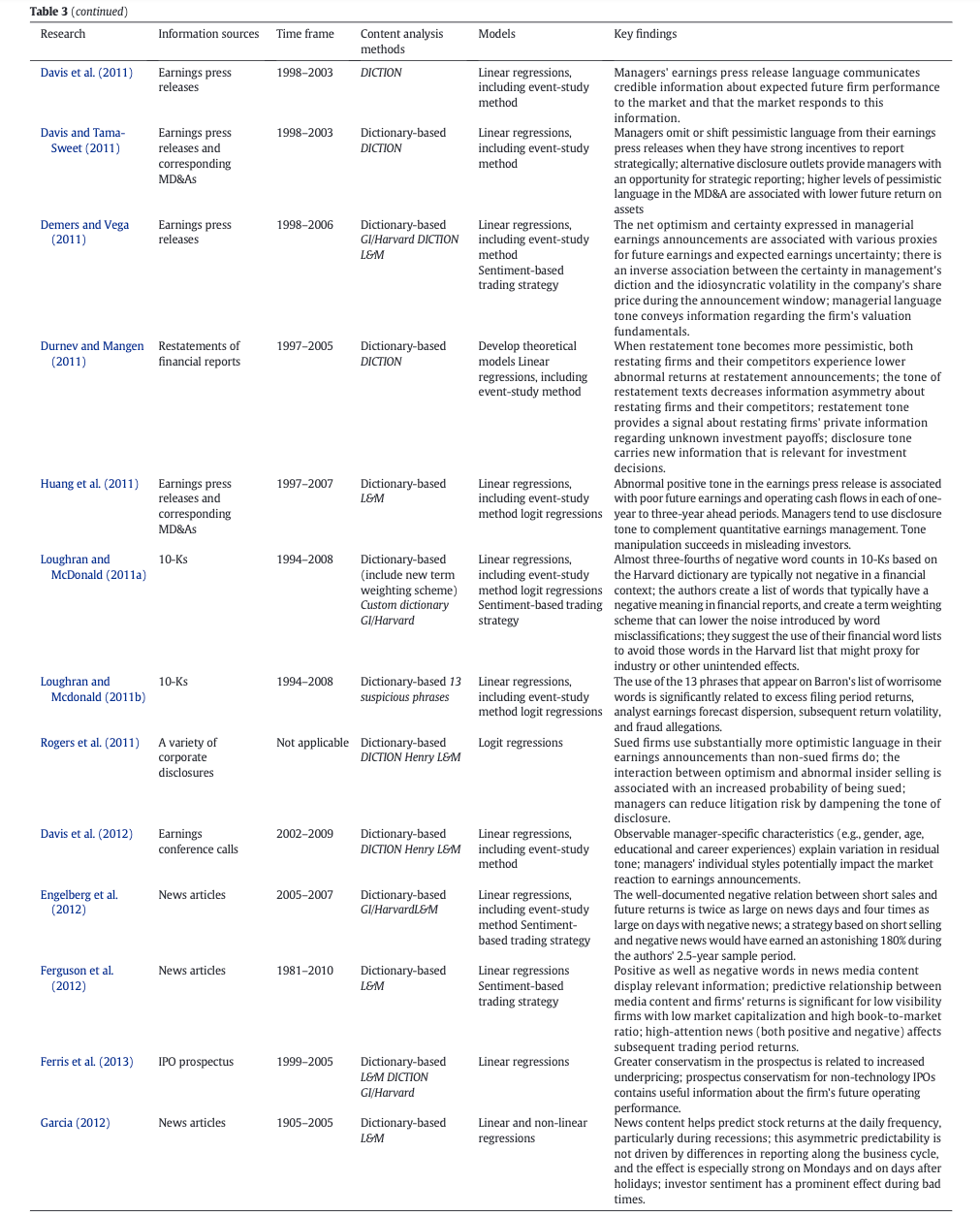
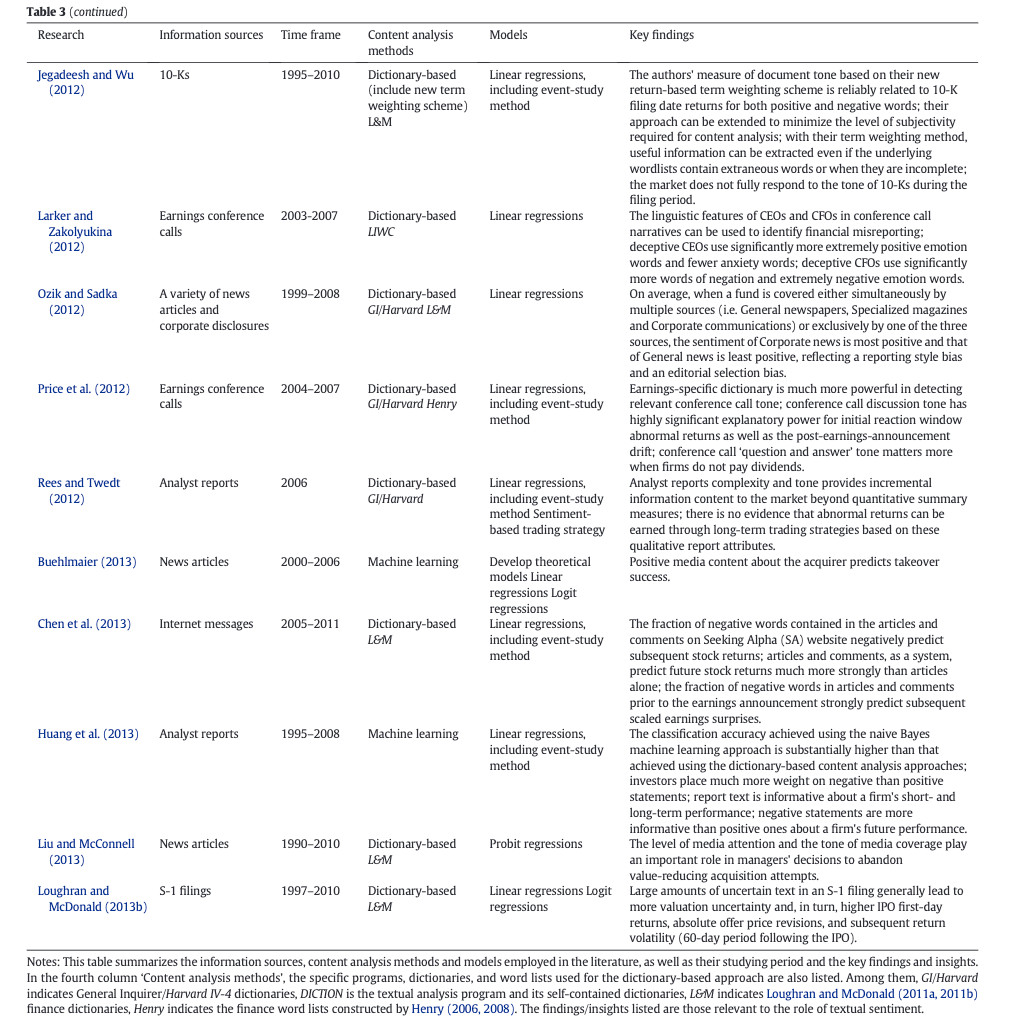
That’s all I have for this post. If you are also interested in applying NLP techniques to finance research, feel free to check out other pieces.
Stay tuned to this series, see you next time!
Reference
- Allee, Kristian D., and Matthew D. Deangelis, 2015, The Structure of Voluntary Disclosure Narratives: Evidence from Tone Dispersion. Journal of Accounting Research 53, 241–74.
- Antweiler, Werner, and Murray Z. Frank, 2004, Is All That Talk Just Noise? The Information Content of Internet Stock Message Boards. The Journal of Finance 59, 1259–1294.
- Buehlmaier, Matthias M M, and Toni M Whited, 2018, Are Financial Constraints Priced? Evidence from Textual Analysis. The Review of Financial Studies 31, 2693–2728.
- Chen, Hailiang, Prabuddha De, Yu Hu, and Byoung-Hyoun Hwang, 2014, Wisdom of Crowds: The Value of Stock Opinions Transmitted Through Social Media. Review of Financial Studies 27, 1367–403.
- Davis, Angela K., Jeremy M. Piger, and Lisa M. Sedor, 2012, Beyond the Numbers: Measuring the Information Content of Earnings Press Release Language. Contemporary Accounting Research 29, 845–68.
- Davis, Angela K., and Isho Tama-Sweet, 2012, Managers’ Use of Language Across Alternative Disclosure Outlets: Earnings Press Releases Versus MD&A. Contemporary Accounting Research 29, 804–37.
- Dougal Casey, Joseph Engelberg, Diego Garcia, and Christopher A. Parsons, 2012, Journalists and the Stock Market. Review of Financial Studies 25, 639–79.
- Feldman, Ronen, Suresh Govindaraj, Joshua Livnat, and Benjamin Segal, 2010, Management’s Tone Change, Post Earnings Announcement Drift and Accruals. Review of Accounting Studies 15, 915– 53.
- Garcia, Diego, 2013, Sentiment During Recessions. Journal of Finance 68, 1267–300.
- Hanley, Kathleen Weis, and Gerard Hoberg, 2010, The Information Content of IPO Prospectuses. Review of Financial Studies 23: 2821–64.
- Huang, Allen H., Amy Y. ZANG, and Rong Zheng, 2014, Evidence on the Information Content of Text in Analyst Reports. The Accounting Review 89, 2151–80.
- Kearney, Colm, and Sha Liu, 2014, Textual sentiment in finance: A survey of methods and models. International Review of Financial Analysis 33, 171–185.
- Kothari, S. P., Xu Li, and James E. Short, 2009, The Effect of Disclosures by Management, Analysts, and Business Press on Cost of Capital, Return Volatility, and Analyst Forecasts: A Study Using Content Analysis. The Accounting Review 84, 1639–70.
- Leuz, Christian, and Catherine M. Schrand, 2009, Disclosure and the Cost of Capital: Evidence from Firms’ Responses to the Enron Shock. Working paper.
- Li, Feng, 2010, Textual Analysis of Corporate Disclosures: A Survey of the Literature. Journal of Accounting Literature 29, 143–65.
- Li, Feng, 2010, The information content of forward-looking statements in corporate filings— A Naive Bayesian machine learning algorithm approach. Journal of Accounting Research 48, 1049-1102.
- Liu, Baixiao, and John J. McConnell, 2013, The Role of the Media in Corporate Governance: Do the Media Influence Managers’ Capital Allocation Decisions? Journal of Financial Economics 110, 1–17.
- Loughran, Tim, and Bill Mcdonald, 2011, When Is a Liability Not a Liability? Textual Analysis, Dictionaries, and 10-Ks. The Journal of Finance 66, 35–65.
- Mayew, William J., and Mohan Venkatachalam, 2012, The Power of Voice: Managerial Affective States and Future Firm Performance. Journal of Finance 67, 1–43.
- Tetlock, Paul C., 2007, Giving Content to Investor Sentiment: The Role of Media in the Stock Market. Journal of Finance 62, 1139–68.
- Tetlock, Paul C., Maytal Saar-Tsechansky, and Sofus Macskassy, 2008, More than Words: Quantifying Language to Measure Firms’ Fundamentals. Journal of Finance 63, 1437–67.